Reinforcement Learning for Cooperative Manipulation
Project in Robot Learning · CS391R · UT Austin · 2021 · with Steven Patrick
An improvement on multi-agent reinforcement learning for cooperative robotic manipulation. We replace the original intrinsic motivation paper's PPO optimizer with DDPG and add Hindsight Experience Replay, achieving faster convergence and a success rate above 90% on OpenAI Fetch pick-and-place.
Pick-and-place demo (learned policy)

Robosuite two-arm lift environment

The problem: making robots cooperate
Single-robot manipulation is well-studied, but coordinating multiple robots to lift a shared object — where each robot's action affects the other — introduces non-stationarity that breaks standard single-agent RL. This project builds on an intrinsic motivation approach that rewards collective over individual actions, and improves it with a more sample-efficient optimizer.
Cooperative task
Two robot arms must jointly lift an object that neither can lift alone. The reward for collective action is defined intrinsically — by comparing the joint outcome to what each agent would achieve individually.
Sparse rewards are hard
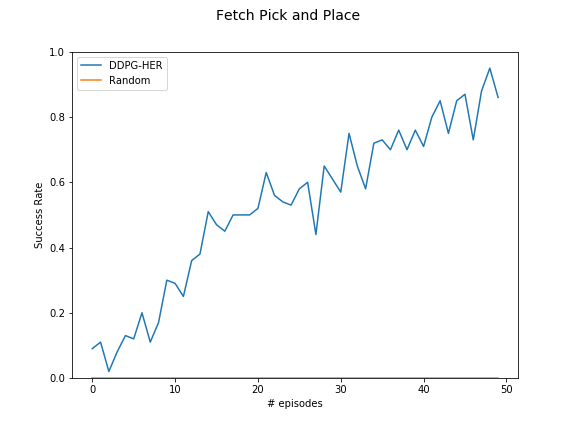
In pick-and-place, the robot only gets a reward when the object reaches the exact goal. With no intermediate feedback, naive DDPG never learns. HER solves this by retroactively treating visited states as goals.
Off-policy data reuse
Unlike PPO (the baseline), DDPG is off-policy: past episode data can be replayed from the buffer. This makes every simulation run more valuable and dramatically reduces training cost.
Three algorithms, one pipeline
The contribution is a specific combination: the intrinsic reward formulation from prior work, upgraded to an off-policy training loop with experience replay. Each piece addresses a distinct failure mode of the others.
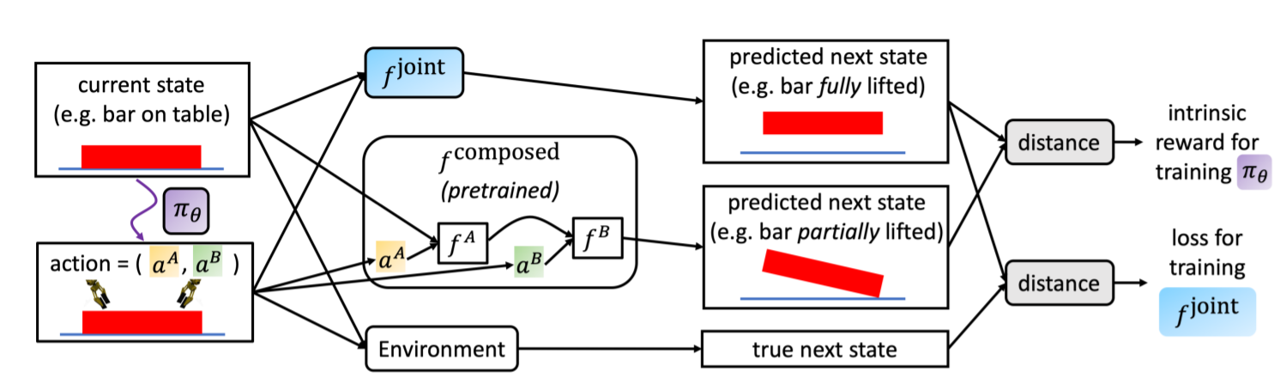
Defines an intrinsic reward as the L2 distance between the predicted next state under joint action vs. chained single-agent actions. Rewards behaviors that require cooperation — actions where individual agents could not produce the same outcome alone.
r_intrinsic = ‖f_joint(s,a) − f_composed(s,a)‖
Deep Deterministic Policy Gradient replaces PPO as the optimizer. Off-policy: episode data is collected with noise-injected actions and stored in a replay buffer for reuse. Suited for continuous action spaces — robot arm joint offsets.
Soft target network updates: θ′ ← τθ + (1−τ)θ′
Augments the replay buffer by relabelling failed episodes with the state the robot actually reached as a substitute goal. Learns from failure. Critical for sparse-reward environments where successes are initially near-impossible to sample.
Goal-agnostic reward structure is a prerequisite — satisfied by all Fetch and Robosuite tasks.
Two simulation testbeds
OpenAI Gym — Fetch
Fetch Reach

Fetch Pick-and-Place

Robosuite
Single-arm lift

Two-arm lift
What worked, what didn't, and why
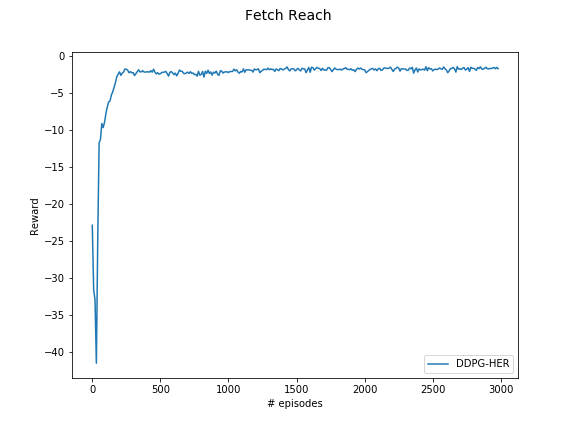
The key finding is that DDPG alone fails on sparse-reward environments, but DDPG+HER reliably solves them. The two-arm lift remained partially unsolved — a reward shaping issue, not an algorithmic one.
DDPG convergence — Fetch Reach (shaped reward)
DDPG+HER success rate — Fetch Pick-and-Place (sparse reward)
Network design
The system has three types of networks. The partial estimators — one per agent — are pre-trained from human demonstrations to predict the next object state given a single agent's action. They are then frozen and chained into f_composed.
The full estimator f_joint takes all agents' actions simultaneously and is trained online. The intrinsic reward is the L2 distance between its prediction and the composed chain — a signal that fires strongly when collective action produces a qualitatively different outcome than the sum of individual actions.
Architecture diagram — joint vs composed estimators
Single-robot baseline environment
