AI Agent for the Squadro Board Game
Personal Project · 2025
An AlphaZero-inspired agent using Monte Carlo Tree Search guided by a self-play-trained policy-value CNN. Outperforms all other implemented algorithms and average human players — including the author.
Demo — Author vs AI
I (yellow) play the Squadro board game against a deep reinforcement-learning agent (red) built from scratch in Python.
What is Squadro?
The Game
Squadro is a two-player board game on a 5×5 grid. The goal is to complete a return trip with four pawns before your opponent. Each pawn moves at a speed determined by the dots at its starting position (1–3). Landing on an opponent's pawn sends it back to the start.
The Challenge
The game tree is large but not infinite — exactly the sweet spot where learned evaluation can sometimes beat pure rollout, and vice versa. This project explores that boundary by pitting eight different algorithms against each other under controlled conditions.
The Result
MCTS Rollout outperforms all agents including the author (human). MCTS Deep Q-Learning is second overall, but beats Rollout at very short time budgets (<0.2s/move), where neural inference costs dominate the search budget.
Eight algorithms, one leaderboard
Every algorithm navigates the same exploration–exploitation tradeoff: explore the game tree, then evaluate the states you reach. The quality of the evaluation and the number of explorations possible within the time budget determines who wins.
MCTS with a policy-value CNN trained by self-play. The AlphaZero variant. Fewer tree searches than rollout but each is guided by a learned neural network.
Beats rollout at <0.2s/move; slower at longer budgets due to CPU inference cost.
MCTS with random playouts to end-of-game as the state evaluator. Simple but fast — runs ~10x more simulations than DQL per move.
Best overall at 3s/move. Small state space makes fast rollouts decisive.
MCTS with a heuristic evaluation function based on relative pawn advancement. No neural network; cheaper per simulation but lower evaluation quality.
Exhaustive tree search to fixed depth with alpha-beta pruning to skip provably suboptimal branches. Deterministic and interpretable.
Greedy one-move lookahead using relative advancement as the evaluation function. No tree search.
Greedy one-move lookahead using absolute advancement (ignores opponent state).
MCTS guided by a learned Q-value lookup table. Practical only for small grids (≤3 pawns) where the state space fits in memory.
Uniformly random move selection. Baseline for all comparisons.
Pairwise win-rate matrix
All agents evaluated head-to-head under identical conditions: max 3 seconds per move, 100 games per pair, original 5×5 grid. Values show the win rate of the row agent against the column agent.
| Row vs Column → | Human | MCTS DQL ★ | MCTS Rollout ★ | MCTS Advancement | AB Relative Advancement | Relative Advancement | Advancement | Random |
|---|---|---|---|---|---|---|---|---|
| Human | — | 0.20 | 0.00 | 0.40 | 0.80 | 1.00 | 1.00 | 1.00 |
| MCTS DQL ★ | 0.80 | — | 0.24 | 0.75 | 0.54 | 1.00 | 1.00 | 1.00 |
| MCTS Rollout ★ | 1.00 | 0.76 | — | 0.94 | 0.77 | 0.98 | 0.99 | 1.00 |
| MCTS Advancement | 0.60 | 0.25 | 0.06 | — | 0.32 | 1.00 | 1.00 | 1.00 |
| AB Relative Advancement | 0.20 | 0.46 | 0.23 | 0.68 | — | 1.00 | 1.00 | 1.00 |
| Relative Advancement | 0.00 | 0.00 | 0.02 | 0.00 | 0.00 | — | 0.50 | 0.97 |
| Advancement | 0.00 | 0.00 | 0.01 | 0.00 | 0.00 | 0.50 | — | 0.95 |
| Random | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.05 | — |
Win rate of the row agent against the column agent over 100 games (max 3 sec/move). ★ = top-tier agents.Green = high win rate · Red = low win rate
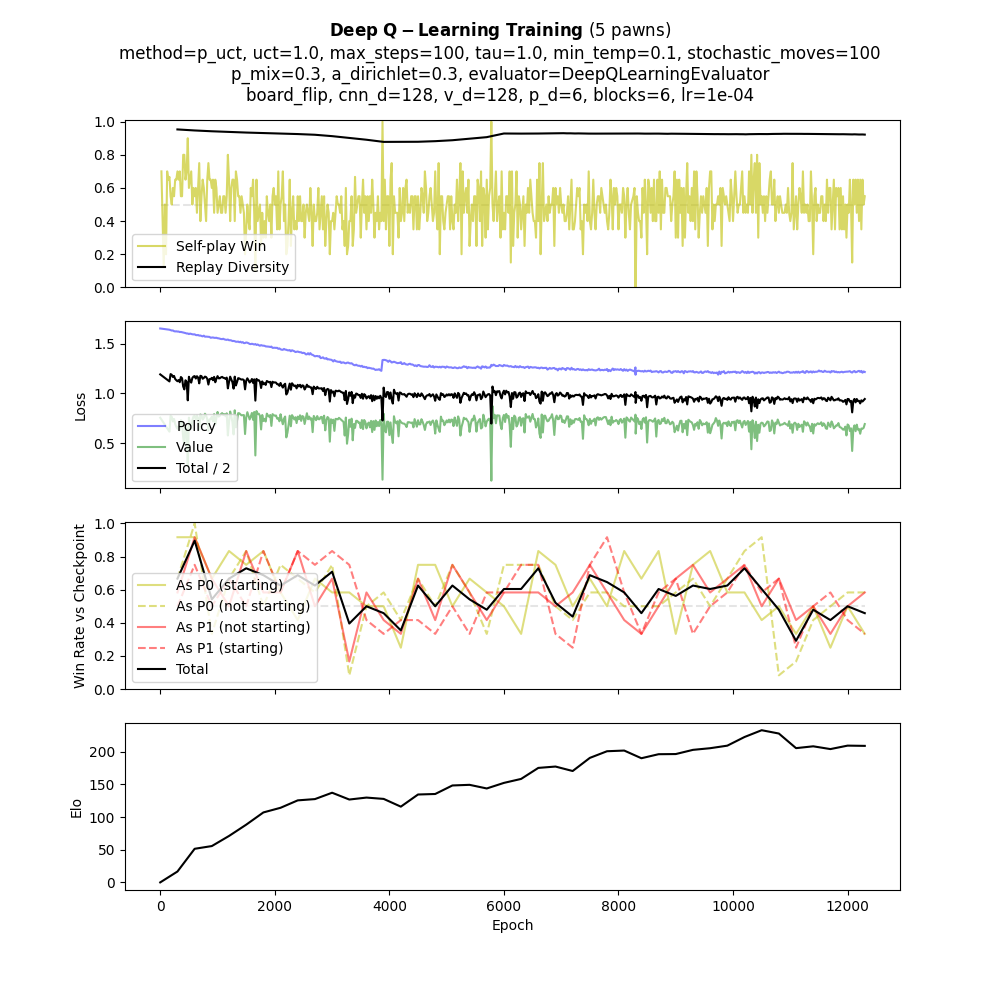
Inside the AlphaZero variant
The MCTS Deep Q-Learning agent is a variant of AlphaZero. Each move is selected by running MCTS guided by a policy-value CNN trained purely through self-play — no human data or hard-coded heuristics.
Several techniques stabilize and accelerate training:
Training Metrics
Pre-trained agents on Hugging Face
No training required — models are downloaded automatically from Hugging Face on first use. All models are lightweight and run well on CPU.
Get started in two commands
pip install squadro
import squadro squadro.GamePlay(agent_1='best').run()
trainer = squadro.DeepQLearningTrainer( n_pawns=5, model_path='my_model' ) trainer.run()